per-cpu variables are widely used in Linux kernel such as per-cpu counters, per-cpu cache. The advantages of per-cpu variables are obvious: for a per-cpu data, we do not need locks to synchronize with other cpus. Without locks, we can gain more performance.
There are two kinds of type of per-cpu variables: static and dynamic. For static variables are defined in build time. Linux provides a DEFINE_PER_CPU macro to defines this per-cpu variables.
One big difference between per-cpu variable and other variable is that we must use per-cpu variable macros to access the real per-cpu variable for a given cpu. Accessing per-cpu variables without through these macros is a bug in Linux kernel programming. We will see the reason later.
Here are two examples of accessing per-cpu variables:
Let's take a closer look at the behaviour of Linux per-cpu variables.
After we define our static per-cpu variables, the complier will collect all static per-cpu variables to the per-cpu sections. We can see them by 'readelf' or 'nm'
tools:
0000000000000000 D __per_cpu_start
...
000000000000f1c0 d lru_add_drain_work
000000000000f1e0 D vm_event_states
000000000000f420 d vmstat_work
000000000000f4a0 d vmap_block_queue
000000000000f4c0 d vfree_deferred
000000000000f4f0 d memory_failure_cpu
...
0000000000013ac0 D __per_cpu_end
You can see our vmstat_work is at 0xf420, which is within __per_cpu_start and __per_cpu_end. The two special symbols (__per_cpu_start and __per_cpu_end) mark the start and end address of the per-cpu section.
One simple question: there are only one entry of vmstat_work in the per-cpu section, but we should have NR_CPUS entries of it. Where are all other vmstat_work entries?
Actually the per-cpu section is just a roadmap of all per-cpu variables. The real body of every per-cpu variable is allocated in a per-cpu chunk at runt-time. Linux make NR_CPUS copies of static/dynamic varables. To get to those real bodies of per-cpu variables, we use per_cpu or per_cpu_ptr macros.
What per_cpu and per_cpu_ptr do is to add a offset (named __per_cpu_offset) to the given address to reach the read body of the per-cpu variable.
Translating a per-cpu variable to its real body (NR_CPUS = 4)
Take a closer look:
There are three part of an unit: static, reserved, and dynamic.
static: the static per-cpu variables. (__per_cpu_end - __per_cpu_start)
reserved: per-cpu slot reserved for kernel modules
dynamic: slots for dynamic allocation (__alloc_percpu)
Unit and chunk
static struct pcpu_alloc_info * __init pcpu_build_alloc_info(
size_t reserved_size, size_t dyn_size,
size_t atom_size,
pcpu_fc_cpu_distance_fn_t cpu_distance_fn)
{
static int group_map[NR_CPUS] __initdata;
static int group_cnt[NR_CPUS] __initdata;
const size_t static_size = __per_cpu_end - __per_cpu_start;
+-- 12 lines: int nr_groups = 1, nr_units = 0;----------------------
/* calculate size_sum and ensure dyn_size is enough for early alloc */
size_sum = PFN_ALIGN(static_size + reserved_size +
max_t(size_t, dyn_size, PERCPU_DYNAMIC_EARLY_SIZE));
dyn_size = size_sum - static_size - reserved_size;
+--108 lines: Determine min_unit_size, alloc_size and max_upa such that--
}
After determining the size of the unit, the chunk is allocated by the
memblock APIs.
int __init pcpu_embed_first_chunk(size_t reserved_size, size_t dyn_size,
size_t atom_size,
pcpu_fc_cpu_distance_fn_t cpu_distance_fn,
pcpu_fc_alloc_fn_t alloc_fn,
pcpu_fc_free_fn_t free_fn)
{
+-- 20 lines: void *base = (void *)ULONG_MAX;---------------------------------
/* allocate, copy and determine base address */
for (group = 0; group < ai->nr_groups; group++) {
struct pcpu_group_info *gi = &ai->groups[group];
unsigned int cpu = NR_CPUS;
void *ptr;
for (i = 0; i < gi->nr_units && cpu == NR_CPUS; i++)
cpu = gi->cpu_map[i];
BUG_ON(cpu == NR_CPUS);
/* allocate space for the whole group */
ptr = alloc_fn(cpu, gi->nr_units * ai->unit_size, atom_size);
if (!ptr) {
rc = -ENOMEM;
goto out_free_areas;
}
/* kmemleak tracks the percpu allocations separately */
kmemleak_free(ptr);
areas[group] = ptr;
base = min(ptr, base);
}
+-- 60 lines: Copy data and free unused parts. This should happen after all---
}
printk is a nature and basic tool for debugging kernel. Sometimes it is the only tool we have. Here are some tips of using printk.
1) printk formats
Documentation/printk-formats.txt introduces many useful printk formats. I use %p family the most:
Raw pointer value SHOULD be printed with %p. The kernel supports
the following extended format specifiers for pointer types:
Symbols/Function Pointers:
%pF versatile_init+0x0/0x110
%pf versatile_init
%pS versatile_init+0x0/0x110
%pSR versatile_init+0x9/0x110
(with __builtin_extract_return_addr() translation)
%ps versatile_init
%pB prev_fn_of_versatile_init+0x88/0x88
2) print_hex_dump
Sometimes I have to create memory dumps. You can use a simple for loop to do that, but Linux kernel provides a better way - print_hex_dump.
For example:
Function prototype:
static inline void print_hex_dump(const char *level, const char *prefix_str,
int prefix_type, int rowsize, int groupsize,
const void *buf, size_t len, bool ascii)
Kernel provides some wrapper macros the different printk levels. I prefer to use the macros because they are more easier to read and less characters to type.
Everytime I do mouse selection in my vim (run in rxvt-unicode) and paste the content to another place, I will select all trailing blanks in every line. It's a very annoying problem.
The slub allocator in Linux has useful debug features. Such as poisoning, readzone checking,
and allocate/free traces with timestamps. It's very useful during product developing stage. Let's create a kernel module and test the debug features.
Make sure slub allocator is built in your kernel.
CONFIG_SLUB_DEBUG=y
CONFIG_SLUB=y
The slub allocator creates additional meta data to store allocate/free
traces and timestamps. Everytime slub allocator allocate/free an object,
it do poison check (data area) and redzone check (boundry).
The module shows how it happens. It allocates 32 bytes from kernel and we overwrite the redzone by memset 36 bytes.
We fill 38 bytes of 0x12 from the start of the 36-bytes object (0xddc86680 - 0xddc8669f) and 4 more 0x12 on the redzone (normal 0xbb or 0xcc). When the object is returned to the kernel, kernel finds that the redzone is neither 0xcc or 0xbb and reports this as a BUG.
The slub allocator reports the latest allocate/free history of this object. You can see the object is just allocated by our kernel module function 'try_to_corrup_redzone'.
Sometime the traces of the object are more useful than function backtrace. For example, if there exists an use-after-free case: function A allocates an object and writes if after freeing the object. If the object is allocated by another function B. In this case, function B has a corrupted object, and if we have the free trace of this object, we can trace back to the previous owner of the object, function A.
One
big problem on 32-bit CPUs is the limited 4GB limitation of virtual
address spaces. The problem remains even if some PAE support since it
focuses on the extension of physical address space not virtual address
space. Things changes after the born of 64-bit CPUs: AMD64 and ARMv8,
they can now support up to 2^64 addresses, which is uhh.. a very big
number.
Actually 2^64 is too large, so in the Linux kernel
implementation, only part of 64 bits are used (42 bits for
CONFIG_ARM64_64K_PAGES, 39 bit for 4K page). This article is assuming 4K
page is used (VA_BITS = 39 case)
One good thing on ARM64 is that since we have enough virtual
address bits, user space and kernel space can have their own 2^39 =
512GB virtual addresses!
All user virtual addresses
have 25 leading zeros and kernel addresses have 25 leading ones. Address
between user space and kernel space are not used and they are used to
trap illegal accesses.
ARM64 Linux virtual address space layout
kernel space:
Although
we have no ARM64 environment now, we can analysis the kernel virtual
address space by reading the source code and observing a running AMD64
Linux box.
In arch/arm64/include/asm/memory.h, we can see the
some differences: we have no lowmem zone, since the virtual address is
so big that we can treat all memory of lowmem and do not have to worry
about virtual address. (Yes, there is still a limit of kernel virtual
address). Second, the order of different kernel virtual address changes:
see also:
arch/arm64/mm/init.c
arch/arm64/include/asm/pgtable.h
You
can see that there is no pkmap or fixmap, it's because the kernel is
assuming every memory has a valid kernel virtual address and there's no
need to create pkmap/fixmap.
ARM64 kernel virtual address space layout
User space:
The
memory layout implementation of user virtual address space looks like
it does on ARM32. Since the available user space virtual address becomes
512GB, we can build a larger application on 64-bit CPUs.
One
interesting topic is that ARM claims the ARMv8 is compatible with ARM
32-bit applications, all 32-bit applications can run on ARMv8 without
modification.How does the 32-bit application virtual memory layout look
like on a 64-bit kernel?
Actually, all process on
64-bit kernel is a 64-bit process. To run ARM 32-bit applications, Linux
kernel still create a process from a 64-bit init process, but limit the
user address space to 4GB. In this way, we can have both 32-bit and
64-bit application on a 64-bit Linux kernel.
ARM64 64-bit user space program virtual address space layout
32-bit ARM applications on 64-bit Linux kernel
ARM64 32-bit user space program virtual address space layout
Note that the 32-bit application still have a 512GB kernel virtual
address space and do not share it's own 4GB of virtual address space
with kernel, the user applications have a complete 4GB of virtual
address. On the other hand, 32-bit applications on 32-bit kernel have
only 3GB of virtual address space.
The 32-bit ARM CPU can address up to 2^32 = 4GB address*. It's not big
enough in present days, since the size of available DRAM on computing
devices is growing fast and the memory usage of application is growing
as well.
In Linux kernel implementation, user space and kernel
must coexist in the same 4GB virtual address space. It means both user
space and kernel can use less than 4GB virtual address space.
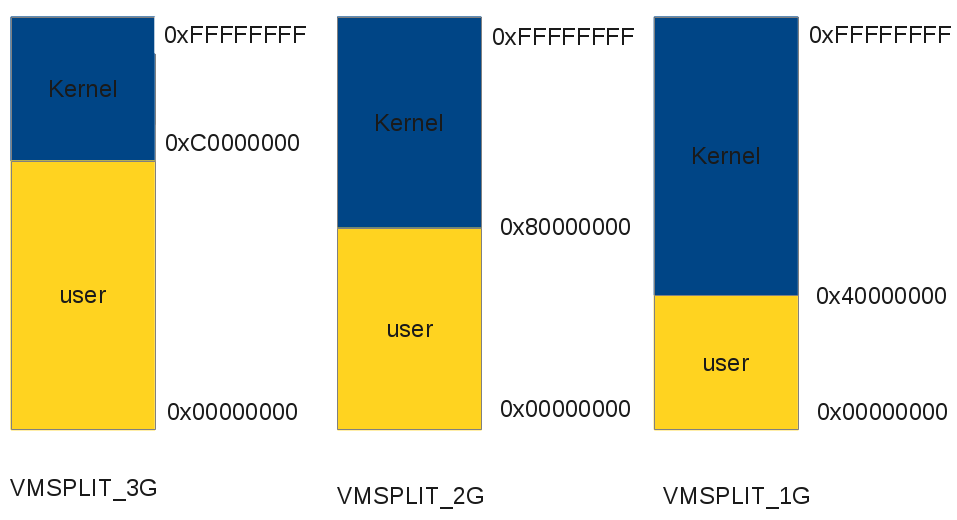
Linux kernel provides 3 different split of virtual address spaces: VMSPLIT_3G, VMSPLIT_2G, VMSPLIT_1G.
Linux virtual address space options
The default configuration is VMSPLIT_3G, as you can see, kernel
space starts from 0xC0000000 to 0xFFFFFFFF and user space starts from
0x00000000 to 0xC0000000.
Let's take a closer look of the VMSPLIT_3G mapping:
kernel space
We can observe the kernel virtual address by checking the boot log (dmesg) or take a look at arch/arm/mm/init.c.
lowmem:
The memory that have 1-to-1 mapping between virtual and physical
address. It means the virtual and physical address are both configuous,
and this good property makes the virtual to physical address translation
very easy. If we have a virtual address from lowmem, we can find out
its physical address by simple shift. (see __pa() and __va()).
vmalloc: The vmalloc memory is only virtually contiguous.
fixmap/pkmap: create fast mapping of a single page for kernel. Most used in file system.
modules: The virtual address for module loading and executing. kernel modules are loaded into this part of virtual memory.
user space
The code for deterring user space virtual address is in arch/arm/mm/mmap.c
The
user space have two different kind of mmap layout: legacy and
non-legacy. Legacy layout sets the base of mmap(TASK_UNMAPPED_BASE) and
the mmap grows in bottom-up manner; on the other case, non-legacy set
the mmap base from TASK_SIZE - 128MB with some random shift for security
reasons).
void arch_pick_mmap_layout(struct mm_struct *mm)
{
unsigned long random_factor = 0UL;
/* 8 bits of randomness in 20 address space bits */
if ((current->flags & PF_RANDOMIZE) &&
!(current->personality & ADDR_NO_RANDOMIZE))
random_factor = (get_random_int() % (1 << 8)) << PAGE_SHIFT;
if (mmap_is_legacy()) {
mm->mmap_base = TASK_UNMAPPED_BASE + random_factor;
mm->get_unmapped_area = arch_get_unmapped_area;
} else {
mm->mmap_base = mmap_base(random_factor);
mm->get_unmapped_area = arch_get_unmapped_area_topdown;
}
The user space virtual address layout looks like:
32-bit user virtual address space layout
*ARM has LPAE (Large Physical Address Extension) mode that can address up to 1TB.